목적 : Floating point model 있을 때 AMD FPGA에서 실행 방법
사용 모델 :
1. Classification : resnet18
2. Detection : yolov5
3. Segmentation : Mobilenet_v2, UNET
실행 환경 : Ubuntu 20.04, Vitis-AI 3.0
Reference : Quick Start Guide for Zynq™ UltraScale+™ — Vitis™ AI 3.0 documentation (xilinx.github.io)
Prerequisit
- 다음과 같은 최소 사양을 만족해야 합니다. Host System Requirements
- 100GB이상의 디스크 여유공간이 있어야 합니다.
Linux setup (WSL 사용)
윈도우 유저라면 윈도우에서 리눅스 kernel에 접속할 수 있게 해주는 WSL을 사용할 수 있습니다. Power shell을 열고 아래와 같은 command를 입력해주세요.
[Powershell] > wsl --install -d Ubuntu-20.04
아래와 같은 command를 통해 사용자는 설치 가능한 모든 distro들을 나열할 수 있습니다.
[Powershell] > wsl --list --online
특정 배포판을 시작하는 방법은 다음과 같습니다.
#설치된 wsl distro list 확인
[Powershell] > wsl --list
#그중 하나를 골라 실행
[Powershell] > wsl -d Ubuntu-20.04
Quickstart
Step 1 - Clone the Vitis AI Repository
아래 명령어를 통해 Vitis-AI 3.0을 설치 해 주세요.
[Host] $ git clone https://github.com/Xilinx/Vitis-AI
Step 2 - Install Docker
Reference : Docker desktop
1. 먼저 Docker Desktop for Windows 링크를 통해 Docker Desktop for windows를 다운 받아 설치 해 줍니다.
2. Docker Desktop for windows를 실행 후, Setting -> General -> Use the WSL 2 based engine에 check, -> Apply&restart를 눌러줍니다.

3. WSL에서 Ubuntu를 설치했다고 가정하겠습니다. 아래 commend를 이용해 Docker를 설치 해 주세요.
#Conflicting될 수 있는 package들을 제거해주세요.
[Host] for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done
# Add Docker's official GPG key:
[Host] sudo apt-get update
[Host] sudo apt-get install ca-certificates curl
[Host] sudo install -m 0755 -d /etc/apt/keyrings
[Host] sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
[Host] sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
[Host] echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
[Host] sudo apt-get update
#Install the Docker packages
[Host] sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
#Docker group을 생성합니다.
[Host] sudo groupadd docker
#User ID를 docker group에 등록합니다.
[Host] sudo usermod -aG docker $USER
#아래 명령어를 입력해서 위 설정이 적용되게 해주세요.
[Host] newgrp docker
- Docker가 잘 설치 되었는지 확인하는 명령어는 아래와 같습니다. 이 command는 Docker Hub로부터 test image를 다운받고, container 안에서 실행 될 것입니다. Docker가 잘 설치 되었다면 "Hello World" message를 출력할 것입니다.
[Host] $ docker run hello-world- 마지막으로 Docker의 version이 최소 사양 Host System Requirements을 충족하는지 확인해 주세요.
[Host] $ docker --version
Step 3 - Pull Vitis AI Docker
그 후, Vitis-AI PyTorch CPU Docker를 pull하고 실행하기 위해 아래 명령어를 입력해 주세요. 미리 build되어 있는 Vitis-AI-Pytorch docker를 불러옴으로서, 다양한 library, compiler등 환경을 구성할 필요 없이 mac/linux등에서 바로 작업을 실행할 수 있습니다.
[Host] $ docker pull xilinx/vitis-ai-pytorch-cpu:latest
Step 4 - Quantizing the Model
1. Vitis-AI directory로 들어가서 새로운 workspace를 만들어 주세요.
[Host] $ cd ~/Vitis-AI
[Host] $ mkdir -p resnet18/model
2. 'resnet18'폴더 아래에 Kaggle에서 ImageNet 1000 (mini) 데이터셋을 다운 받아 주세요. 이 데이터셋은 ILSVRC 2012-2017 데이터셋의 일부로, 1000개의 객체 클래스를 포함하고 있으며, 1,281,167개의 훈련 이미지, 50,000개의 검증 이미지, 그리고 100,000개의 테스트 이미지로 이루어져 있습니다.

그 후, 압축을 풀어주세요.
[Host] $ cd resnet18
[Host] $ unzip archive.zip
그러면 workspace directory는 아래와 같이 구성 되어 있을 것입니다.
├── archive.zip
│
├── model
│
└── imagenet-mini
├── train # Training images folder. Will not be used in this tutorial.
│ └─── n01440764 # Class folders to group images.
└── val # Validation images that will be used for quantization and evaluation of the floating point model.
└─── n01440764
3. Vitis-AI directory로 가셔서 Docker를 시작해 주세요.
[Host] $ cd ..
[Host] ./docker_run.sh xilinx/vitis-ai-pytorch-cpu:latest
- Docker의 /workspace folder와 ~/Vitis-AI 폴더가 일치합니다.
workspace에 /resnet18 folder가 생성되었는지 확인 해 주세요.
[Docker] $ ls
4. 이미 training되어있는 resnet18 model을 다운로드 받아주세요.
[Docker] $ cd resnet18/model
[Docker] $ wget https://download.pytorch.org/models/resnet18-5c106cde.pth -O resnet18.pth
5. ResNet18 quantization script를 workspace의 resnet18폴더에 copy해주세요. 이 script는 Quantizer API를 이용하고 있습니다.
[Docker] $ cp /workspace/src/vai_quantizer/vai_q_pytorch/example/resnet18_quant.py /workspace/resnet18/
workspace/resnet18 directory의 device tree는 아래와 같습니다.
├── archive.zip
│
├── model
│ └── resnet18.pth # ResNet18 floating point model downloaded from PyTorch.
│
├── imagenet-mini
│ ├── train # Training images folder. Will not be used in this tutorial.
│ │ └─── n01440764 # Class folders to group images.
│ └── val # Validation images that will be used for quantization and evaluation of the floating point model.
│ └─── n01440764
│
└── resnet18_quant.py # Quantization python script.
resnet18_quant.py script를 보면 parser argument에 대한 설명들이 있습니다.
[Docker] $ vim resnet18_quant.py
아무것도 저장하지 않고 나가시려면 <esc> :q!를 사용해 주세요.

6. Floating model의 accuracy를 검증하려면 아래 command를 입력해 주세요. Dataset으로 아까 다운받았던 imagenet-mini를 사용하고, resnet18.pth모델이 들어있는 폴더를 지정합니다. 현재 floating model의 accuray를 검증하기 위해 --quant_mode를 float으로 설정합니다.
[Docker] $ python resnet18_quant.py --quant_mode float --data_dir imagenet-mini --model_dir model
위 command를 입력 하셨을 때, accuracy는 top-1 / top-5 accuracy : 69.9975/88.7586 이 나옵니다.

7. 다음으로, Model inspector를 실행해서 target DPU architecture와 호환되는지 확인해주세요.
[Docker] $ python resnet18_quant.py --quant_mode float --inspect --target DPUCZDX8G_ISA1_B4096 --model_dir model아래 파일은 inspect한 후, log를 기록한 파일입니다.
+ Known error
ModuleNotFoundError: No module named 'tabulate' => pip install tabulate
8. Quantization을 시작하기 위해 아래 code를 입력 해주세요. 일반적으로 100-1000개의 이미지들이 quantization을 위해 필요합니다. 반복 횟수는 'subset_len' data loading argument를 통해 조절이 가능합니다.
[Docker] $ python resnet18_quant.py --quant_mode calib --data_dir imagenet-mini --model_dir model --subset_len 200
위 명령어를 실행하면 1분 내외로 실행이 마쳐질 것입니다. GPU docker를 이용하면 시간이 더 단축될 수 있습니다.

[Docker] $ cd quantize_result
[Docker] $ ls만약 command가 성공적으로 돌아갔다면, 'quantize_result'라는 output directory가 생성됬을 것입니다. 다음과 같은 2개의 파일을 포함하고 있습니다.
- ResNet.py : quantized된 vai_q_pytorch format model
- Quant_info.json : Quantize model evaluation을 위해 이 파일을 보관해주세요.

9. Quantized model의 accuracy를 evaluate하기 위해, 아래와 같은 명령어를 실행해 주세요. 약 20분 정도 걸릴 것입니다. 이 코드가 성공적으로 실행되면, top-1/top-5 accuracy : 69.1308/88.7076과 비슷한 정확도를 확인할 수 있을 것입니다.
[Docker] $ cd ..
[Docker] $ python resnet18_quant.py --model_dir model --data_dir imagenet-mini --quant_mode test결과
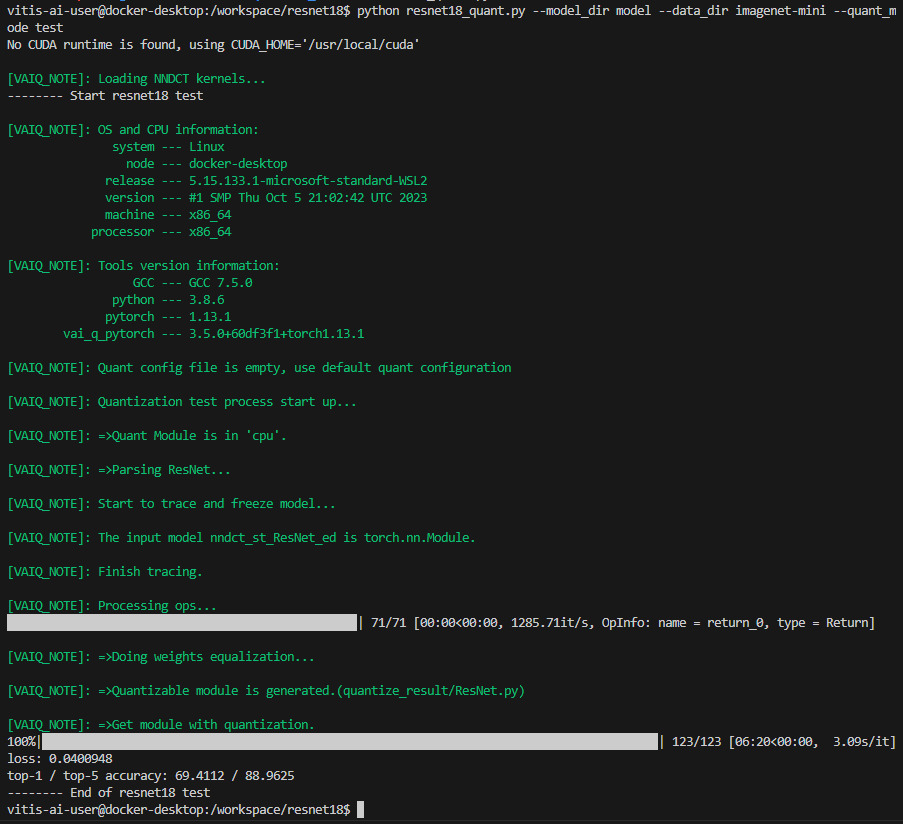
10. Quantized된 .xmodel을 생성하기 위해, 아래 command를 실행 해 주세요. model 내보내기의 경우 여러 반복이 필요하지 않으므로 'bat_size', 'subset_len' argument를 1로 설정해야 합니다.
[Docker] $ python resnet18_quant.py --quant_mode test --subset_len 1 --batch_size=1 --model_dir model --data_dir imagenet-mini --deploy
아래는 실행 결과 파일입니다.
Step 5 - Compile the model
Vitis-AI Compiler는 graph operator를 이용해 DPU를 돌리기 위한 instruction으로 compile을 합니다. 이번 step에선 이전에 quantized했던 ResNet18 model을 compile해보겠습니다.
1. Compiler는 quantized된 'INT8.xmdoel'을 이용하여 보드에서 돌릴 수 있는 'DPU.xmodel'을 생성합니다.이를 위해 적절한 DPU arch.json파일이 필요합니다. Zynq MPSoC를 위한 arch.json파일은 Docker안에서 /opt/vitis_ai/compiler/arch/DPUCZDX8G에 위치하고 있습니다.
[Docker] $ cd /workspace/resnet18
[Docker] $ vai_c_xir -x quantize_result/ResNet_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/<Target ex:KV260>/arch.json -o resnet18_pt -n resnet18_pt
결과 log입니다.

만약 compile이 제대로 됬다면, resnet18_pt.xmodel이 생성되었을 것입니다.

2. texteditor (ex. vim)을 이용해 'resnet18_pt.prototxt'파일을 만들고 아래 내용을 copy&paste 해주세요.
model {
name : "resnet18_pt"
kernel {
name: "resnet18_pt_0"
mean: 103.53
mean: 116.28
mean: 123.675
scale: 0.017429
scale: 0.017507
scale: 0.01712475
}
model_type : CLASSIFICATION
classification_param {
top_k : 5
test_accuracy : false
preprocess_type : VGG_PREPROCESS
}
}



Step 6 - Model Deployment
이 과정은 compile된 xmodel을 이용해 Board에서 resnet18을 돌리는 과정입니다.
1. scp명령어를 이용해 만들어진 folder를 보드로 옮겨주세요.
[Docker] $ scp -r resnet18_pt root@[TARGET_IP_ADDRESS]:/usr/share/vitis_ai_library/models/
2. vitis_ai_library_r3.0.0_images.tar.gz 과 vitis_ai_library_r3.0.0_video.tar.gz 패키지들은 각각 test image와 test video를 포함합니다.
#Package를 다운받아주세요
[Docker] $ cd /workspace
[Docker] $ wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_images.tar.gz -O vitis_ai_library_r3.0.0_images.tar.gz
[Docker] $ wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_video.tar.gz -O vitis_ai_library_r3.0.0_video.tar.gz
#파일을 SCP를 이용해 보드로 전송해주세요
[Docker] $ scp -r vitis_ai_library_r3.0.0_images.tar.gz root@[TARGET_IP_ADDRESS]:~/
[Docker] $ scp -r vitis_ai_library_r3.0.0_video.tar.gz root@[TARGET_IP_ADDRESS]:~/
#보드에서 파일을 압축 해제 해주세요
[Target] $ tar -xzvf vitis_ai_library_r3.0.0_images.tar.gz -C ~/Vitis-AI/examples/vai_library/
[Target] $ tar -xzvf vitis_ai_library_r3.0.0_video.tar.gz -C ~/Vitis-AI/examples/vai_library/
3. Sample directory에 들어가서 compile해주세요. 시간이 조금 걸릴 수 있습니다.
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/classification
[Target] $ ./build.sh
4. single-image test application을 실행 해주세요.
[Target] $ ./test_jpeg_classification resnet18_pt ~/Vitis-AI/examples/vai_library/samples/classification/images/002.JPEG
결과입니다. brain coral이라는 label로 판단 했고, confidence는 0.999702입니다.

5, Video example을 실행시키기 위해 아래 command를 입력해주세요. (ssh 연결 필요)
[Target] $ ./test_video_classification resnet18_pt ~/Vitis-AI/examples/vai_library/apps/seg_and_pose_detect/pose_960_540.avi -t 8
아래 사진은 위 커멘드 실행 결과 나온 비디오의 순간을 캡쳐한 것입니다.

Detection 모델을 test해보고 싶다면 (ex. yolov5)
1. yolov5 폴더에 들어가서 compile을 해줍니다.
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/yolov5
[Target] $ ./build.sh
2. single-image test application을 실행 해주세요. 실행 가능한 모델은 보드의 '/usr/share/vitis_ai_library/models'에서 확인 가능합니다.
[Target] $ ./test_jpeg_yolov5 yolov5_nano_pt sample_yolov5.jpg

3. Video example을 실행시키기 위해 아래 command를 입력해주세요.
[Target] $ ./test_video_yolov5 yolov5_nano_pt ~/Vitis-AI/examples/vai_library/apps/seg_and_pose_detect/pose_960_540.avi -t 8
아래 사진은 위 커멘드 실행 결과 나온 비디오의 순간을 캡쳐한 것입니다. 객체에 검은색 박스가 쳐져 있고, FPS가 15정도 나오는 것을 알 수 있습니다.

Segmentation model을 test해보고 싶다면(ex. )
1. segmentation 폴더에 들어가서 compile을 해줍니다.
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/segmentation
[Target] $ ./build.sh
2. single-image test application을 실행 해주세요. 실행 가능한 모델은 보드의 '/usr/share/vitis_ai_library/models'에서 확인 가능합니다.
[Target] $ ./test_jpeg_segmentation mobilenet_v2_cityscapes_tf sample_segmentation.jpg

결과

3. Video example을 실행시키기 위해 아래 command를 입력해주세요.
[Target] $ ./test_video_yolov5 yolov5_nano_pt ~/Vitis-AI/examples/vai_library/apps/seg_and_pose_detect/pose_960_540.avi -t 8
아래 사진은 위 커멘드 실행 결과 나온 비디오의 순간을 캡쳐한 것입니다.
/test_video_yolov5 yolov5_nano_pt ~/Vitis-AI/examples/vai_library/apps/segs_and_roadline_detect/seg_512_288.avi -t 8
./test_video_segmentation SemanticFPN_Mobilenetv2_pt ~/Vitis-AI/examples/vai_library/apps/segs_and_roadline_detect/seg_512_288.avi -t 8
[추가 예정]
감사합니다.
+ 아래 사진은 위 커멘드 실행 결과 나온 비디오의 순간을 캡쳐한 것입니다.
Yolov3(obj.)
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/yolov3
[Target] $ ./build.sh
[Target] $ ./test_video_yolov3 yolov3_voc ~/Vitis-AI/examples/vai_library/apps/segs_and_roadline_detect/seg_512_288.avi -t 8

./test_accuracy_yolov3_voc yolov3_voc ./images/001.png
yolov3_accuracy_result.txt -t 2
(-t는 thread입니다)
accuracy test방법
#image file list가 들어있는 .txt파일을 만들어줍니다.
[Target] $ vim test_performance_yolov3.list
[In the vim environment] wq image_list.txt
[Target] $ vim
#accuracy 결과가 저장 될 txt파일을 만들어줍니다.
[Target] $ yolov3_voc_accuracy.txt
#accuracy check을 위해 아래 코드를 실행합니다.
./test_accuracy_yolov3_mt yolov3_bdd image_list.txt yolov3_voc_accuracy.txt -t 2아래는 결과 파일입니다.
Unet(seg.)
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/segmentation
[Target] $ ./build.sh
[Target] $ ./test_jpeg_segmentation unet_chaos-CT_pt sample_segmentation_chaos.jpg
현재 Vitis-AI-library에선 Unet은 Medical Segmentation용으로 supporting하고 있습니다.
그 외, fpn model을 사용한 결과입니다.
[Target] $ ./test_video_segmentation SemanticFPN_Mobilenetv2_pt ~/Vitis-AI/examples/vai_library/apps/segs_and_roadline_detect/seg_512_288.avi -t 8
VGGNet(class.)
[Target] $ cd ~/Vitis-AI/examples/vai_library/samples/classification
[Target] $ ./build.sh
[Target] $ ./test_video_classification vgg_16_tf ~/Vitis-AI/examples/vai_library/apps/segs_and_roadline_detect/seg_512_288.avi -t 8
